На главную страницу
Рекурсивные запросы в SQL:1999 и SQL Server 2005
Frederic BROUARD (оригинал: Recursive Queries in SQL:1999 and SQL Server 2005)
Перевод Моисеенко С.И.
Резюме:
Каждый хотя бы однажды за свою жизнь имел опыт использования рекурсии. Когда я был
молод, однажды находился в отпуске в Париже в старом здании, в котором коридор имел
две зеркальные стены. Когда я прошел между этими зеркалами, мое тело было отражено
бесконечное число раз, и я был очень горд, радостно восхищаясь моим изображением
и имея конкретное представление бесконечности. Это и есть рекурсия... Процесс, который
способен воспроизводить сам себя в течение некоторого промежутка времени.
В механических ситуациях мы не принимаем бесконечную рекурсию. В реальном мире мы
должны иметь точку останова, потому что наша вселенная замкнута. Ожидание окончания
бесконечного процесса, который фактически является вечностью, является тяжкой работой!
Как говорит Вуди Аллен: "вечность действительно длинна, особенно вблизи конца
..."
В компьютерном смысле рекурсия - это специальный метод, который иногда позволяет
обработать сложные алгоритмы в изящном стиле кодирования: несколько строк сделают
всю работу. Но рекурсия имеет некоторые побочные эффекты: ресурсы, необходимые для
работы, максимизируются тем фактом, что каждый вызов вложенного процесса должен
открывать полное пространство окружающей среды, что приводит к использованию большого
объема памяти. Математик, чье имя я не могу вспомнить, говорит, что каждый рекурсивный
алгоритм может быть сведен к итерационному при помощи стека!
Но наша цель сейчас состоит в том, чтобы поговорить о РЕКУРСИВНЫХ ЗАПРОСАХ
в SQL в части стандарта ISO (Международной Организации по Стандартизации) и того,
как MS SQL Server 2005 обошелся с ними.
1 - Стандарт ISO SQL:1999
Вот краткий синтаксис РЕКУРСИВНОГО ЗАПРОСА:
WITH [ RECURSIVE ] <имя_алиаса_запроса> [ ( <список столбцов> ) ]
AS (<запрос select> )
<запрос, использующий имя_алиаса_запроса>
Просто! Не так ли? Фактически, вся механика находится внутри <запрос select >.
Мы рассмотрим сначала простые не рекурсивные запросы, и когда поймем, что мы можем
сделать с ключевым словом WITH, мы сорвем занавес, чтобы обнажить рекурсию в SQL.
2 - Простой CTE
Использование только предложения WITH (без ключевого слова RECURSIVE) призвано построить
Общее Табличной Выражение (CTE). Фактически CTE - это представление, построенное
специально для запроса и используемое однократно: всякий раз, когда мы выполняем
запрос. В некотором смысле его можно назвать "непостоянным представлением".
Основное назначение CTE - сделать более понятным некоторое выражение, которое неоднократно
включается в более сложный запрос. Основной пример:
-- если существует таблица для примера, удалить ее
IF EXISTS (SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = USER
AND TABLE_NAME = 'T_NEWS')
DROP TABLE T_NEWS
GO
-- создать таблицу
CREATE TABLE T_NEWS
(NEW_ID INTEGER NOT NULL PRIMARY KEY,
NEW_FORUM VARCHAR(16),
NEW_QUESTION VARCHAR(32))
GO
-- заполнить данными
INSERT INTO T_NEWS VALUES (1, 'SQL', 'What is SQL ?')
INSERT INTO T_NEWS VALUES (2, 'SQL', 'What do we do now ?')
INSERT INTO T_NEWS VALUES (3, 'Microsoft', 'Is SQL 2005 ready for use ?')
INSERT INTO T_NEWS VALUES (4, 'Microsoft', 'Did SQL2000 use RECURSION ?')
INSERT INTO T_NEWS VALUES (5, 'Microsoft', 'Where am I ?')
-- традиционный запрос:
SELECT COUNT(NEW_ID) AS NEW_NBR, NEW_FORUM
FROM T_NEWS
GROUP BY NEW_FORUM
HAVING COUNT(NEW_ID) = ( SELECT MAX(NEW_NBR)
FROM ( SELECT COUNT(NEW_ID) AS NEW_NBR,
NEW_FORUM
FROM T_NEWS
GROUP BY NEW_FORUM ) T )
-- Результат :
NEW_NBR NEW_FORUM
----------- ----------------
3 Microsoft
Этот запрос один из самых популярных на многих форумах, то есть он вызывает наибольшее
число вопросов. Чтобы построить запрос, нам необходимо определить MAX(COUNT (...),
что не допускается и, таким образом, должно быть выполнено с помощью подзапросов.
Но в вышеупомянутом запросе содержится два абсолютно одинаковых оператора SELECT:
SELECT COUNT(NEW_ID) AS NEW_NBR, NEW_FORUM
FROM T_NEWS
GROUP BY NEW_FORUM
С использованием CTE мы можем теперь сделать запрос более читабельным:
WITH
Q_COUNT_NEWS (NBR, FORUM)
AS
(SELECT COUNT(NEW_ID), NEW_FORUM
FROM T_NEWS
GROUP BY NEW_FORUM)
SELECT NBR, FORUM
FROM Q_COUNT_NEWS
WHERE NBR = (SELECT MAX(NBR)
FROM Q_COUNT_NEWS)
Фактически, мы используем непостоянное представление Q_COUNT_NEWS, вводимое выражением
WITH, чтобы написать в более изящной форме решение нашей задачи. Подобно представлению,
Вы должны дать имя CTE, а также дать новые имена столбцам, которые содержатся в
предложении SELECT в CTE, что не является обязательным.
Отметим, что Вы можете использовать два, три или больше CTE для построения запроса...
Давайте рассмотрим еще один пример:
WITH
Q_COUNT_NEWS (NBR, FORUM)
AS
(SELECT COUNT(NEW_ID), NEW_FORUM
FROM T_NEWS
GROUP BY NEW_FORUM),
Q_MAX_COUNT_NEWS (NBR)
AS (SELECT MAX(NBR)
FROM Q_COUNT_NEWS)
SELECT T1.*
FROM Q_COUNT_NEWS T1
INNER JOIN Q_MAX_COUNT_NEWS T2
ON T1.NBR = T2.NBR
Он дает те же самые результаты, что и два предыдущих варианта! Первый CTE - Q_COUNT_NEWS
- используется как таблица во втором, и эти два CTE соединяются в запросе, чтобы
дать окончательный результат. Обратите внимание на запятую, которая разделяет два
CTE.
3 - Два трюка для рекурсии
Чтобы сделать рекурсию, синтаксис SQL нуждается в двух трюках:
ПЕРВЫЙ: Вы должны предоставить начальную точку рекурсии. Это должно делаться с помощью
запроса, состоящего из двух частей. Первый запрос сообщает, откуда начинать, а второй
запрос говорит, где перейти к следующему шагу. Эти два запроса объединяются теоретико-множественным
оператором UNION ALL.
ВТОРОЙ: Вы должны связать CTE и SQL внутри CTE (Inside out, outside in, - была такая
популярная песня в стиле диско ... помните?), чтобы обеспечить пошаговое выполнение.
Это делается посредством <имя_алиаса_запроса> внутри SQL, который строит CTE.
4 - Первый пример: простая иерархия
Для этого примера, я создаю таблицу, которая содержит типологию транспортных средств:
-- Если таблица существует, удалить ее
IF EXISTS (SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = USER
AND TABLE_NAME = 'T_VEHICULE')
DROP TABLE T_VEHICULE
-- Создать таблицу
CREATE TABLE T_VEHICULE
(VHC_ID INTEGER NOT NULL PRIMARY KEY,
VHC_ID_FATHER INTEGER FOREIGN KEY REFERENCES T_VEHICULE (VHC_ID),
VHC_NAME VARCHAR(16))
-- Наполнить данными
INSERT INTO T_VEHICULE VALUES (1, NULL, 'ALL')
INSERT INTO T_VEHICULE VALUES (2, 1, 'SEA')
INSERT INTO T_VEHICULE VALUES (3, 1, 'EARTH')
INSERT INTO T_VEHICULE VALUES (4, 1, 'AIR')
INSERT INTO T_VEHICULE VALUES (5, 2, 'SUBMARINE')
INSERT INTO T_VEHICULE VALUES (6, 2, 'BOAT')
INSERT INTO T_VEHICULE VALUES (7, 3, 'CAR')
INSERT INTO T_VEHICULE VALUES (8, 3, 'TWO WHEELES')
INSERT INTO T_VEHICULE VALUES (9, 3, 'TRUCK')
INSERT INTO T_VEHICULE VALUES (10, 4, 'ROCKET')
INSERT INTO T_VEHICULE VALUES (11, 4, 'PLANE')
INSERT INTO T_VEHICULE VALUES (12, 8, 'MOTORCYCLE')
INSERT INTO T_VEHICULE VALUES (13, 8, 'BYCYCLE')
Обычно иерархия схематизируется авто-ссылкой, которая имеет место и здесь: внешний
ключ ссылается на первичный ключ той же таблицы. Имеющиеся данные можно трактовать
следующим образом:
ALL
|--SEA
| |--SUBMARINE
| |--BOAT
|--EARTH
| |--CAR
| |--TWO WHEELES
| | |--MOTORCYCLE
| | |--BYCYCLE
| |--TRUCK
|--AIR
|--ROCKET
|--PLANE
Теперь давайте построим запрос. Мы хотим узнать, откуда пришел МОТОЦИКЛ (MOTORCYCLE).
Другими словами, требуется найти всех предков "МОТОЦИКЛА". Начать следует
со строки данных, которая содержат motorbyke:
SELECT VHC_NAME, VHC_ID_FATHER
FROM T_VEHICULE
WHERE VHC_NAME = 'MOTORCYCLE'
Мы должны иметь родительский ID, чтобы перейти к следующему шагу. Второй запрос,
который делает этот следующий шаг, должен быть написан подобно следующему:
SELECT VHC_NAME, VHC_ID_FATHER
FROM T_VEHICULE
Как Вы видите, запросы отличаются только тем, что мы не задаем фильтр WHERE для
перехода к следующему шагу. Напомню, что мы должны объединить эти два запроса с
помощью UNION ALL, что определит пошаговый метод:
SELECT VHC_NAME, VHC_ID_FATHER
FROM T_VEHICULE
WHERE VHC_NAME = 'MOTORCYCLE'
UNION ALL
SELECT VHC_NAME, VHC_ID_FATHER
FROM T_VEHICULE
Давайте теперь разместим все это в CTE:
WITH
tree (data, id)
AS (SELECT VHC_NAME, VHC_ID_FATHER
FROM T_VEHICULE
WHERE VHC_NAME = 'MOTORCYCLE'
UNION ALL
SELECT VHC_NAME, VHC_ID_FATHER
FROM T_VEHICULE)
Теперь мы вплотную подошли к рекурсии. Последний шаг должен сделать цикл, чтобы
организовать выполнение пошагового метода. Это делается при использовании имени
CTE в качестве таблицы внутри SQL-запроса CTE. В нашем случае мы должны соединить
второй запрос CTE с самим CTE, организовав цепочку по tree.id = (второй запрос).VHC_ID.
Это можно сделать следующим образом:
WITH
tree (data, id)
AS (SELECT VHC_NAME, VHC_ID_FATHER
FROM T_VEHICULE
WHERE VHC_NAME = 'MOTORCYCLE'
UNION ALL
SELECT VHC_NAME, VHC_ID_FATHER
FROM T_VEHICULE V
INNER JOIN tree t
ON t.id = V.VHC_ID)
SELECT *
FROM tree
Осталось лишь написать самый простой SELECT, чтобы вывести данные. Теперь, если
Вы для выполнения запроса нажмете кнопку F5, то увидите следующее:
data
id
---------------- -----------
MOTORCYCLE 8
TWO WHEELES 3
EARTH 1
ALL NULL
Теперь взгляните еще раз на связи, которые делают пошаговую обработку, в графическом
представлении:
correlation
______________________________________
| |
v |
WITH tree (data, id) |
AS (SELECT VHC_NAME, VHC_ID_FATHER |
FROM T_VEHICULE |
WHERE VHC_NAME = 'MOTORCYCLE' |
UNION ALL |
SELECT VHC_NAME, VHC_ID_FATHER |
FROM T_VEHICULE V |
INNER JOIN tree t <---------------
ON t.id = V.VHC_ID)
SELECT *
FROM tree
Кстати, а что остановило рекурсивный процесс? Факт, что больше нет звеньев цепочки,
когда достигается значение id "NULL", что в нашем примере означает случай
достижения "ALL".
Теперь Вы получаете метод. Отметим, что по неясным причинам MS SQL Server 2005 не
допускает ключевого слова RECURSIVE после слова WITH, которое вводит CTE. Но 2005
пока находится в бета версии и, таким образом, мы можем ожидать, что оно появится
в финальной версии продукта.
5 - Иерархическое представление
Еще одна важная вещь, связанная со структурированными в форме деревьев данными,
- это визуализация данных в виде дерева ..., что означает наличие отступов в иерархии
при извлечении данных. Возможно ли это? Да, конечно. Порядок требует знания пути,
уровня для размещения пробельных символов и id или timestamp строки в случае наличия
строк с одинаковым размещением в дереве (многолистовые данные). Это может быть сделано
вычислением пути внутри рекурсии. Вот пример такого запроса:
WITH tree (data, id, level,
pathstr)
AS (SELECT VHC_NAME, VHC_ID, 0,
CAST('' AS VARCHAR(MAX))
FROM T_VEHICULE
WHERE VHC_ID_FATHER IS NULL
UNION ALL
SELECT VHC_NAME, VHC_ID, t.level +
1, t.pathstr + V.VHC_NAME
FROM T_VEHICULE V
INNER JOIN tree t
ON t.id
= V.VHC_ID_FATHER)
SELECT SPACE(level) + data as data, id, level, pathstr
FROM tree
ORDER BY pathstr, id
|
data |
|
id |
|
level |
|
pathstr |
|
ALL |
|
1 |
|
0 |
|
AIR |
|
4 |
|
4 |
|
AIR |
|
PLANE |
|
11 |
|
2 |
|
AIRPLANE |
|
ROCKET |
|
10 |
|
2 |
|
AIRROCKET |
|
EARTH |
|
3 |
|
1 |
|
EARTH |
|
CAR |
|
7 |
|
2 |
|
EARTHCAR |
|
TRUCK |
|
9 |
|
2 |
|
EARTHTRUCK |
|
TWO WHEELES |
|
8 |
|
2 |
|
EARTHTWO WHEELES
|
|
BYCYCLE |
|
13 |
|
3 |
|
EARTHTWO WHEELESBYCYCLE
|
|
MOTORCYCLE |
|
12 |
|
3 |
|
EARTHTWO WHEELESMOTORCYCLE |
|
SEA |
|
2 |
|
1 |
|
SEA |
|
BOAT |
|
6 |
|
2 |
|
SEABOAT |
|
SUBMARINE |
|
5 |
|
2 |
|
SEASUBMARINE |
Чтобы сделать это, нам потребовалось использовать новый тип данных в SQL 2005, который
называется VARCHAR (MAX), поскольку мы не знаем максимального количества символов,
которое потребуется при конкатенации VARCHAR (16) в рекурсивном запросе, который
может оказаться очень глубоким. Заметим, что это не очень хорошая идея строить путь
с помощью VARCHAR, поскольку это может привести к некоторым граничным эффектам типа
конкатенации 'LAND' и 'MARK' на уровне 2 дерева, что может быть ошибочно воспринято
как 'LANDMARK' уровня 1 в другой ветви того же самого дерева. Таким образом, Вы
должны предусмотреть пробел в конкатенированном пути, чтобы избежать подобных проблем.
Это может быть сделано преобразованием типа VHC_NAME к CHAR.
6 - Деревья без рекурсии
Однако я должен сказать, что иерархические данные не очень интересны! Почему? Поскольку
есть другие способы обработки данных. Помните, я говорил Вам, что математик может
сказать, что "Вы можете избежать рекурсии при использовании стека"? Действительно
ли это возможно в нашем случае?
Да!
Только поместите стек внутрь таблицы. Как? При помощи двух новых столбцов:
ALTER TABLE T_VEHICULE
ADD RIGHT_BOUND INTEGER
ALTER TABLE T_VEHICULE
ADD LEFT_BOUND INTEGER
Теперь, как фокусник, я заполню эти новые столбцы некоторыми хитрыми числами:
UPDATE T_VEHICULE SET LEFT_BOUND = 1 , RIGHT_BOUND = 26 WHERE VHC_ID = 1
UPDATE T_VEHICULE SET LEFT_BOUND = 2 , RIGHT_BOUND = 7 WHERE VHC_ID = 2
UPDATE T_VEHICULE SET LEFT_BOUND = 8 , RIGHT_BOUND = 19 WHERE VHC_ID = 3
UPDATE T_VEHICULE SET LEFT_BOUND = 20, RIGHT_BOUND = 25 WHERE VHC_ID = 4
UPDATE T_VEHICULE SET LEFT_BOUND = 3 , RIGHT_BOUND = 4 WHERE VHC_ID = 5
UPDATE T_VEHICULE SET LEFT_BOUND = 5 , RIGHT_BOUND = 6 WHERE VHC_ID = 6
UPDATE T_VEHICULE SET LEFT_BOUND = 9 , RIGHT_BOUND = 10 WHERE VHC_ID = 7
UPDATE T_VEHICULE SET LEFT_BOUND = 11, RIGHT_BOUND = 16 WHERE VHC_ID = 8
UPDATE T_VEHICULE SET LEFT_BOUND = 17, RIGHT_BOUND = 18 WHERE VHC_ID = 9
UPDATE T_VEHICULE SET LEFT_BOUND = 21, RIGHT_BOUND = 22 WHERE VHC_ID = 10
UPDATE T_VEHICULE SET LEFT_BOUND = 23, RIGHT_BOUND = 24 WHERE VHC_ID = 11
UPDATE T_VEHICULE SET LEFT_BOUND = 12, RIGHT_BOUND = 13 WHERE VHC_ID = 12
UPDATE T_VEHICULE SET LEFT_BOUND = 14, RIGHT_BOUND = 15 WHERE VHC_ID = 13
И вот волшебный запрос, дающий тот же самый результат, что и сложный иерархический
рекурсивный запрос:
SELECT *
FROM T_VEHICULE
WHERE RIGHT_BOUND > 12
AND LEFT_BOUND < 13
|
VHC_ID |
|
VHC_ID_FATHER |
|
VHC_NAME |
|
RIGHT_BOUND |
|
LEFT_BOUND |
|
1 |
|
NULL |
|
ALL |
|
26 |
|
1 |
|
3 |
|
1 |
|
EARTH |
|
19 |
|
8 |
|
8 |
|
3 |
|
TWO WHEELES |
|
16 |
|
11 |
|
12 |
|
8 |
|
MOTORCYCLE |
|
13 |
|
12 |
Вопрос: так в чем прикол?
Фактически мы реализовали стек, нумеруя слои данных. Вот поясняющая картинка:
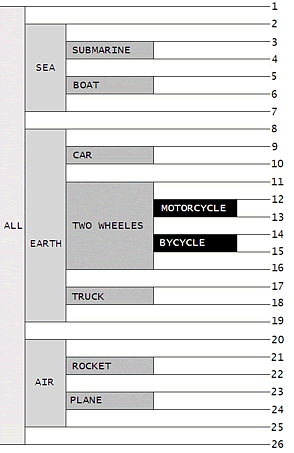
Единственная вещь, которую я должен сделать, - это перенумеровать последовательно
начиная с 1 справа налево все стеки, составленные каждым элементом данных. Теперь,
чтобы получить вышеприведенный запрос, я только беру границы МОТОЦИКЛА (MOTORCYCLE)
- слева 12, а справа 13 - и помещаю их в предложение WHERE, выбирая данные, правая
граница которых превышает 12, а левая меньше 13.
Кстати говоря, рисунок станет более понятным, если повернуть его на 90 градусов
против часовой стрелки.
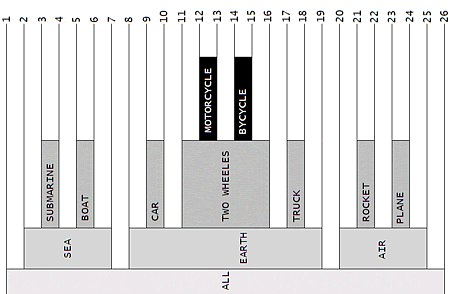
Вы видите здесь стеки? Такое представление деревьев хорошо известно в литературе
по базам данных, особенно в трудах Джо Селко. Вы найдете все, что пожелаете, в его
знаменитой книге "Деревья и иерархии", вышедшей под редакцией Morgan Kaufman
в серии "SQL для умников". Если вы читаете по-французски, могу порекомендовать
еще один ресурс, где можно найти хранимые процедуры, написанные для MS SQL Server
и выполняющие всю работу, связанную с этой моделью:
http://sqlpro.developpez.com/cours/arborescence/
Наконец, можем мы воспроизвести иерархические отступы как в последнем запросе? Да,
конечно. Это будет намного легче сделать, если ввести еще один столбец 'LEVEL' для
хранения уровня узла. Его можно очень просто вычислить, поскольку при вставке в
дерево первый узел - это корень и, следовательно, его уровень - 0. При вставке других
элементов в дерево уровень вычисляется по родительским данным: если вставляется
дочерний узел, то его уровень есть уровень родителя + 1. Чтобы вставить сестринский
элемент, заимствуется уровень сестры. Ниже приведены операторы ALTER и UPDATE, которые
расставляют уровни в таблице:
ALTER TABLE T_VEHICULE
ADD LEVEL INTEGER
UPDATE T_VEHICULE SET LEVEL = 0 WHERE VHC_ID = 1
UPDATE T_VEHICULE SET LEVEL = 1 WHERE VHC_ID = 2
UPDATE T_VEHICULE SET LEVEL = 1 WHERE VHC_ID = 3
UPDATE T_VEHICULE SET LEVEL = 1 WHERE VHC_ID = 4
UPDATE T_VEHICULE SET LEVEL = 2 WHERE VHC_ID = 5
UPDATE T_VEHICULE SET LEVEL = 2 WHERE VHC_ID = 6
UPDATE T_VEHICULE SET LEVEL = 2 WHERE VHC_ID = 7
UPDATE T_VEHICULE SET LEVEL = 2 WHERE VHC_ID = 8
UPDATE T_VEHICULE SET LEVEL = 2 WHERE VHC_ID = 9
UPDATE T_VEHICULE SET LEVEL = 2 WHERE VHC_ID = 10
UPDATE T_VEHICULE SET LEVEL = 2 WHERE VHC_ID = 11
UPDATE T_VEHICULE SET LEVEL = 3 WHERE VHC_ID = 12
UPDATE T_VEHICULE SET LEVEL = 3 WHERE VHC_ID = 13
Теперь запрос, делающий отступы, примет вид:
SELECT SPACE(LEVEL) + VHC_NAME as data
FROM T_VEHICULE
ORDER BY LEFT_BOUND
Намного проще, не так ли?
ПЕРВЫЕ ВПЕЧАТЛЕНИЯ...
Единственное, что можно сказать об этих двух способах навигации по иерархическим
данным, - это то, что интервальная модель значительно более эффективна и работает
лучше, чем модель, использующая технику рекурсивных запросов SQL:1999. Фактически,
РЕКУРСИВНЫЕ запросы не так здесь интересны... А где-то еще?... Да!
7 - Второй пример: сложная сеть
Возможно Вы никогда не были во Франции. Поэтому может вам будет интересно узнать,
что в Париже красивые девушки, в Тулузе знаменитое блюдо называют мясным ассорти,
и маленький конструктор самолета называется Аэробус.
Итак, проблема состоит в том, чтобы проехать на машине от Парижа до Тулузы, используя
сеть автострад. Я несколько упрощаю схему для Вас (если Вы потерялись и не знаете,
как произнести название города, чтобы спросить дорогу до Тулузы, просто скажите
"to loose" (распустить) ...):
PARIS
|
------------------------------------
| |
|
385 420
470
| |
|
NANTES CLERMONT FERRAND LYON
| |
|
| | 335
305 | 320
| ---------- -----------------
|
| | |
375 | MONTPELLIER
MARSEILLE
|
| |
----------------------
205
| 240
|
TOULOUSE
NICE
-- если существует необходимая нам для примера таблица, удалить
ее
IF EXISTS (SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = USER
AND TABLE_NAME = 'T_JOURNEY')
DROP TABLE T_JOURNEY
-- создать таблицу:
CREATE TABLE T_JOURNEY
(JNY_FROM_TOWN VARCHAR(32),
JNY_TO_TOWN VARCHAR(32),
JNY_MILES INTEGER)
-- занести данные :
INSERT INTO T_JOURNEY VALUES ('PARIS', 'NANTES', 385)
INSERT INTO T_JOURNEY VALUES ('PARIS', 'CLERMONT-FERRAND', 420)
INSERT INTO T_JOURNEY VALUES ('PARIS', 'LYON', 470)
INSERT INTO T_JOURNEY VALUES ('CLERMONT-FERRAND', 'MONTPELLIER', 335)
INSERT INTO T_JOURNEY VALUES ('CLERMONT-FERRAND', 'TOULOUSE', 375)
INSERT INTO T_JOURNEY VALUES ('LYON', 'MONTPELLIER', 305)
INSERT INTO T_JOURNEY VALUES ('LYON', 'MARSEILLE', 320)
INSERT INTO T_JOURNEY VALUES ('MONTPELLIER', 'TOULOUSE', 240)
INSERT INTO T_JOURNEY VALUES ('MARSEILLE', 'NICE', 205)
Теперь попробуем очень простой вопрос, дающий все поездки между городами:
WITH journey (TO_TOWN)
AS
(SELECT DISTINCT JNY_FROM_TOWN
FROM T_JOURNEY
UNION ALL
SELECT JNY_TO_TOWN
FROM T_JOURNEY AS arrival
INNER JOIN journey AS departure
ON departure.TO_TOWN = arrival.JNY_FROM_TOWN)
SELECT *
FROM journey
TO_TOWN
-----------------
CLERMONT-FERRAND
LYON
MARSEILLE
MONTPELLIER
PARIS
NANTES
CLERMONT-FERRAND
LYON
MONTPELLIER
MARSEILLE
NICE
TOULOUSE
MONTPELLIER
TOULOUSE
TOULOUSE
TOULOUSE
NICE
MONTPELLIER
MARSEILLE
NICE
TOULOUSE
MONTPELLIER
TOULOUSE
TOULOUSE
Этот запрос не очень интересен, поскольку мы не знаем, из какого города мы туда
приехали. Мы лишь получили города, куда мы можем добраться, и тот факт, что мы имеем,
вероятно, разные варианты добраться до одного и того же места. Давайте посмотрим,
не сможем ли мы добыть еще немного информации...
Начнем с Парижа:
WITH journey (TO_TOWN)
AS
(SELECT DISTINCT JNY_FROM_TOWN
FROM T_JOURNEY
WHERE JNY_FROM_TOWN = 'PARIS'
UNION ALL
SELECT JNY_TO_TOWN
FROM T_JOURNEY AS arrival
INNER JOIN journey AS departure
ON departure.TO_TOWN = arrival.JNY_FROM_TOWN)
SELECT *
FROM journey
TO_TOWN
--------------------------------
PARIS
NANTES
CLERMONT-FERRAND
LYON
MONTPELLIER
MARSEILLE
NICE
TOULOUSE
MONTPELLIER
TOULOUSE
TOULOUSE
По-видимому имеется три способа добраться до Тулузы. Можем ли мы отфильтровать пункт
назначения? Конечно!
WITH journey (TO_TOWN)
AS
(SELECT DISTINCT JNY_FROM_TOWN
FROM T_JOURNEY
WHERE JNY_FROM_TOWN = 'PARIS'
UNION ALL
SELECT JNY_TO_TOWN
FROM T_JOURNEY AS arrival
INNER JOIN journey AS departure
ON departure.TO_TOWN = arrival.JNY_FROM_TOWN)
SELECT *
FROM journey
WHERE TO_TOWN = 'TOULOUSE'
TO_TOWN
---------------
TOULOUSE
TOULOUSE
TOULOUSE
Мы можем уточнить этот запрос, подсчитав число шагов по каждому направлению:
WITH journey (TO_TOWN, STEPS)
AS
(SELECT DISTINCT JNY_FROM_TOWN, 0
FROM T_JOURNEY
WHERE JNY_FROM_TOWN = 'PARIS'
UNION ALL
SELECT JNY_TO_TOWN, departure.STEPS + 1
FROM T_JOURNEY AS arrival
INNER JOIN journey AS departure
ON departure.TO_TOWN = arrival.JNY_FROM_TOWN)
SELECT *
FROM journey
WHERE TO_TOWN = 'TOULOUSE'
TO_TOWN STEPS
------------- -----------
TOULOUSE 3
TOULOUSE 2
TOULOUSE 3
А вот расстояния по различным направлениям:
WITH journey (TO_TOWN, STEPS, DISTANCE)
AS
(SELECT DISTINCT JNY_FROM_TOWN, 0, 0
FROM T_JOURNEY
WHERE JNY_FROM_TOWN = 'PARIS'
UNION ALL
SELECT JNY_TO_TOWN, departure.STEPS + 1,
departure.DISTANCE
+ arrival.JNY_MILES
FROM T_JOURNEY AS arrival
INNER JOIN journey AS departure
ON departure.TO_TOWN
= arrival.JNY_FROM_TOWN)
SELECT *
FROM journey
WHERE TO_TOWN = 'TOULOUSE'
TO_TOWN STEPS DISTANCE
--------------- ----------- -------------------
TOULOUSE 3 1015
TOULOUSE 2
795
TOULOUSE 3
995
Теперь узнаем разные города, которые мы посетим, двигаясь по этим направлениям:
WITH journey (TO_TOWN, STEPS, DISTANCE, WAY)
AS
(SELECT DISTINCT JNY_FROM_TOWN, 0, 0, CAST('PARIS'
AS VARCHAR(MAX))
FROM T_JOURNEY
WHERE JNY_FROM_TOWN = 'PARIS'
UNION ALL
SELECT JNY_TO_TOWN, departure.STEPS + 1,
departure.DISTANCE + arrival.JNY_MILES,
departure.WAY
+ ', ' + arrival.JNY_TO_TOWN
FROM T_JOURNEY AS arrival
INNER JOIN journey AS departure
ON departure.TO_TOWN = arrival.JNY_FROM_TOWN)
SELECT *
FROM journey
WHERE TO_TOWN = 'TOULOUSE'
TO_TOWN STEPS DISTANCE WAY
--------- ------ ---------- ------------------------------------------------
TOULOUSE 3 1015
PARIS, LYON, MONTPELLIER, TOULOUSE
TOULOUSE 2 795
PARIS, CLERMONT-FERRAND, TOULOUSE
TOULOUSE 3 995 PARIS,
CLERMONT-FERRAND, MONTPELLIER, TOULOUSE
Теперь, леди и джентльмены, РЕКУРСИВНЫЙ ЗАПРОС рад представить Вам решение очень
сложной задачи, названной задачей коммивояжера (одна из действительных проблем исследования,
на которых Edsger Wybe Dijkstra нашел первый эффективный алгоритм и получил премию
Turing Award в 1972):
WITH journey (TO_TOWN, STEPS, DISTANCE, WAY)
AS
(SELECT DISTINCT JNY_FROM_TOWN, 0, 0, CAST('PARIS' AS VARCHAR(MAX))
FROM T_JOURNEY
WHERE JNY_FROM_TOWN = 'PARIS'
UNION ALL
SELECT JNY_TO_TOWN, departure.STEPS + 1,
departure.DISTANCE + arrival.JNY_MILES,
departure.WAY + ', ' + arrival.JNY_TO_TOWN
FROM T_JOURNEY AS arrival
INNER JOIN journey AS departure
ON departure.TO_TOWN
= arrival.JNY_FROM_TOWN)
SELECT TOP 1 *
FROM journey
WHERE TO_TOWN = 'TOULOUSE'
ORDER BY DISTANCE
TO_TOWN STEPS DISTANCE
WAY
---------- ------- ---------- ---------------------------------
TOULOUSE 2
795 PARIS, CLERMONT-FERRAND, TOULOUSE
Между прочим, TOP n - нестандартная для SQL конструкция... Избегайте ее... Наслаждайтесь
CTE!
WITH
journey (TO_TOWN, STEPS, DISTANCE, WAY)
AS
(SELECT DISTINCT JNY_FROM_TOWN,
0, 0, CAST('PARIS' AS VARCHAR(MAX))
FROM T_JOURNEY
WHERE JNY_FROM_TOWN = 'PARIS'
UNION ALL
SELECT JNY_TO_TOWN, departure.STEPS + 1,
departure.DISTANCE + arrival.JNY_MILES,
departure.WAY + ', ' + arrival.JNY_TO_TOWN
FROM T_JOURNEY AS arrival
INNER JOIN journey AS departure
ON departure.TO_TOWN = arrival.JNY_FROM_TOWN),
short (DISTANCE)
AS
(SELECT MIN(DISTANCE)
FROM journey
WHERE TO_TOWN = 'TOULOUSE')
SELECT *
FROM journey j
INNER JOIN short s
ON j.DISTANCE = s.DISTANCE
WHERE TO_TOWN = 'TOULOUSE'
8 - Что еще мы можем сделать?
Фактически, только одно ограничение имеется в нашей обработке сети автострад; это
то, что мы построили маршруты в одном направлении. Я имею в виду, что мы можем проехать
из Парижа до Лиона, но нам не позволено совершить поездку из Лиона до Парижа. Для
этого мы должны добавить обратные пути в таблицу, например:
JNY_FROM_TOWN JNY_TO_TOWN JNY_MILES
-------------- ------------ ----------------------
LYON PARIS 470
Это может быть сделано с помощью очень простого запроса:
INSERT INTO T_JOURNEY
SELECT JNY_TO_TOWN, JNY_FROM_TOWN, JNY_MILES
FROM T_JOURNEY
Однако проблема состоит в том, что представленные выше запросы не будут работать
правильно:
А вот расстояния по различным направлениям:
WITH journey (TO_TOWN)
AS
(SELECT DISTINCT JNY_FROM_TOWN
FROM T_JOURNEY
WHERE JNY_FROM_TOWN = 'PARIS'
UNION ALL
SELECT JNY_TO_TOWN
FROM T_JOURNEY AS arrival
INNER JOIN journey AS departure
ON departure.TO_TOWN
= arrival.JNY_FROM_TOWN)
SELECT *
FROM journey
TO_TOWN
------------------
PARIS
NANTES
CLERMONT-FERRAND
LYON
...
LYON
MONTPELLIER
MARSEILLE
PARIS
Msg 530, Level 16, State 1, Line 1
The statement terminated. The maximum recursion 100 has been exhausted before statement
completion.
(Выполнение оператора прервано. Максимальная рекурсия в 100 итераций была исчерпана
до завершения оператора.)
Что случилось? Все просто, Вы пытаетесь перебрать все пути, включая циклические
типа Париж, Лион, Париж, Лион, Париж ... и так до бесконечности... Есть ли способ
избежать периодически повторяющихся маршрутов? Возможно. В одном из наших предыдущих
запросов, мы получили столбец, который дает полный список пройденных городов. Почему
бы не использовать его, чтобы избежать зацикливания? Условие будет таким: не проезжайте
через город, который уже встречался нам на ПУТИ. Это условие можно записать следующим
образом:
WITH journey (TO_TOWN, STEPS, DISTANCE, WAY)
AS
(SELECT DISTINCT JNY_FROM_TOWN, 0, 0, CAST('PARIS' AS VARCHAR(MAX))
FROM T_JOURNEY
WHERE JNY_FROM_TOWN = 'PARIS'
UNION ALL
SELECT JNY_TO_TOWN, departure.STEPS + 1,
departure.DISTANCE + arrival.JNY_MILES,
departure.WAY + ', ' + arrival.JNY_TO_TOWN
FROM T_JOURNEY AS arrival
INNER JOIN journey AS departure
ON departure.TO_TOWN
= arrival.JNY_FROM_TOWN
WHERE departure.WAY NOT LIKE '%' + arrival.JNY_TO_TOWN
+ '%')
SELECT *
FROM journey
WHERE TO_TOWN = 'TOULOUSE'
TO_TOWN STEPS DISTANCE WAY
-------- ------ --------- ---------------------------------------------------------
TOULOUSE 3
1015 PARIS, LYON, MONTPELLIER,
TOULOUSE
TOULOUSE 4
1485 PARIS, LYON, MONTPELLIER,
CLERMONT-FERRAND, TOULOUSE
TOULOUSE 2 795 PARIS, CLERMONT-FERRAND, TOULOUSE
TOULOUSE 3 995 PARIS, CLERMONT-FERRAND, MONTPELLIER,
TOULOUSE
Как видно, возник новый маршрут. Худший по расстоянию, но возможно самый красивый!
ЗАКЛЮЧЕНИЕ
CTE может упростить выражение сложных запросов. РЕКУРСИВНЫЕ запросы должны использоваться
там, где рекурсия необходима. Если Вы напишите плохой вопрос в MS SQL Server, не
бойтесь, циклы рекурсий ограничены числом 100. Вы можете преодолеть этот предел
с помощью OPTION (MAXRECURSION n), где n - необходимое вам значение. Предложение
OPTION должно быть последним в выражении CTE. Но помните одну вещь: MS SQL Server
2005 фактически находится бета версии!
Наконец, ISO SQL:1999 имел еще некоторые варианты синтаксиса, которые могут позволить
Вам выполнять навигацию по данным: DEPTH FIRST (первый в глубину) или BREADTH FIRST
(первый в ширину), а также по всем данным, содержавшимся в шагах (в массиве строки,
который должен иметь "достаточный" размер, чтобы покрыть все случаи!).
Вот синтаксис:
WITH [ RECURSIVE ] [ ( <liste_colonne> ) ]
AS ( <requete_select> )
[ <clause_cycle_recherche> ]
with :
<clause_cycle_recherche> ::=
<clause_recherche>
| <clause_cycle>
| <clause_recherche> <clause_cycle>
and :
<clause_recherche> ::=
SEARCH { DEPTH FIRTS BY
| BREADTH FIRST BY } <liste_specification_ordre>
SET <colonne_sequence>
<clause_cycle> ::=
CYCLE <colonne_cycle1> [ { , <colonne_cycle2>
} ... ]
SET <colonne_marquage_cycle>
TO <valeur_marque_cycle>
DEFAULT <valeur_marque_non_cycle>
USING <colonne_chemin>
Вонус (CTE, рекурсивно примененный запрос)
Ниже приведен запрос в хранимой процедуре, которая может дать точный порядок таблиц
для удаления перед удалением таблицы, на которую имеются ссылки по внешнему ключу:
CREATE PROCEDURE P_WHAT_TO_DELETE_BEFORE
@TABLE_TO_DELETE VARCHAR(128), -- Таблица,
которую требуется удалить
@DB VARCHAR(128),
-- база данных
@USR VARCHAR(128)
-- схема (dbo в большинстве случаев)
AS
WITH T_CONTRAINTES (table_name, father_table_name)
AS (SELECT DISTINCT CTU.TABLE_NAME, TCT.TABLE_NAME
FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS RFC
INNER JOIN INFORMATION_SCHEMA.CONSTRAINT_TABLE_USAGE
CTU
ON RFC.CONSTRAINT_CATALOG
= CTU.CONSTRAINT_CATALOG
AND RFC.CONSTRAINT_SCHEMA = CTU.CONSTRAINT_SCHEMA
AND RFC.CONSTRAINT_NAME = CTU.CONSTRAINT_NAME
INNER JOIN
INFORMATION_SCHEMA.TABLE_CONSTRAINTS TCT
ON RFC.UNIQUE_CONSTRAINT_CATALOG = TCT.CONSTRAINT_CATALOG
AND RFC.UNIQUE_CONSTRAINT_SCHEMA = TCT.CONSTRAINT_SCHEMA
AND RFC.UNIQUE_CONSTRAINT_NAME = TCT.CONSTRAINT_NAME
WHERE CTU.TABLE_CATALOG = @DB
AND CTU.TABLE_SCHEMA
= @USR)
,T_TREE_CONTRAINTES (table_to_delete, level)
AS (SELECT DISTINCT table_name, 0
FROM T_CONTRAINTES
WHERE father_table_name = @TABLE_TO_DELETE
UNION ALL
SELECT priorT.table_name, level
- 1
FROM T_CONTRAINTES priorT
INNER JOIN
T_TREE_CONTRAINTES beginT
ON beginT.table_to_delete = priorT.father_table_name
WHERE priorT.father_table_name
<> priorT.table_name)
SELECT DISTINCT *
FROM T_TREE_CONTRAINTES
ORDER BY level
GO
Учтен случай самосоединения. Параметры: @DB (имя базы данных),
@USR (имя схемы: dbo),
@TABLE_TO_DELETE (таблица, которую Вы хотите удалить).
Библиографический список:
" Le langage SQL : Frederic Brouard, Christian Soutou - Pearson Education 2005
(France)
" Joe Celko's Trees & Hierarchies in SQL for Smarties : Joe Celko - Morgan
Kaufmann 2004
" SQL:1999 : J. Melton, A. Simon - Morgan Kauffman, 2002
" SQL developpement : Frederic Brouard - Campus Press 2001 (France)
" SQL for Dummies : Allen G. Taylor - Hungry Minds Inc 2001
" SQL-99 complete really : P. Gulutzan, T. Pelzer - R&D Books, 1999
" SQL 3, Implementing the SQL Foundation Standard : Paul Fortier - Mc Graw
Hill, 1999
" SQL for smarties : Joe Celko - Morgan Kaufmann 1995
О самом коротком алгоритме Dijkstra для задачи коммивояжера и других распространенных
задачах, см.: www.hsor.org/downloads/Speedy_Delivery_teacher.pdf
15-09-2006
На главную страницу